혼자 공부하는 머신러닝 + 딥러닝 2주차
- 혼자 공부하는 머신러닝 + 딥러닝 1주차
- 혼자 공부하는 머신러닝 + 딥러닝 2주차
- 혼자 공부하는 머신러닝 + 딥러닝 3주차
- 혼자 공부하는 머신러닝 + 딥러닝 4주차
- 혼자 공부하는 머신러닝 + 딥러닝 5주차
- 혼자 공부하는 머신러닝 + 딥러닝 6주차 (완)
머신러닝을 정리할 겸 한빛미디어가 진행하는 혼공 학습단 5기에 참여했다. 3장에 대해 학습을 진행했다.
기본 미션
기본 미션은 3-1절 문제의 그래프를 인증하는 것이다. 아래와 같이 풀었다.
knr = KNeighborsRegressor()
x = np.arange(5, 45).reshape(-1, 1)
for n in [1, 5, 10]:
knr.n_neighbors = n
knr.fit(train_input, train_target)
prediction = knr.predict(x)
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.show()
k-최근접 이웃 회귀(KNeighborsRegressor)를 사용할 때 참조하는 이웃의 개수(n_neighbors)에 따라 어떻게 학습에 영향을 줄지 확인하기 위한 과제.
x = np.arange(5, 45).reshape(-1, 1)
np.arange(5, 45)로 5에서 44까지(45 앞)의 수를 생성하고 reshape를 이용해서 열은 개수는 -1이기 때문에 데이터를 기반으로 추론하고, 행의 개수는 1로 변형.
for n in [1, 5, 10]:
knr.n_neighbors = n
루프를 돌며 참조하는 이웃의 개수(n_neighbors)를 1, 5, 10으로 수정해 봄.
knr.fit(train_input, train_target)
prediction = knr.predict(x)
학습 데이터(train_input)과 학습 타겟으로 다시 학습한다.
plt.scatter(train_input, train_target)
plt.plot(x, prediction)
plt.show()
출력된 산포도 그래프는 아래와 같다.
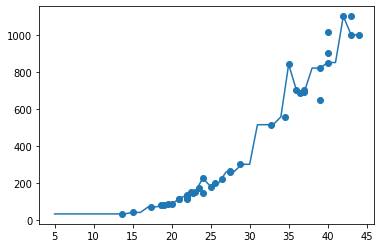 n_neighbors가 1로 설정된 그래프
n_neighbors가 1로 설정된 그래프
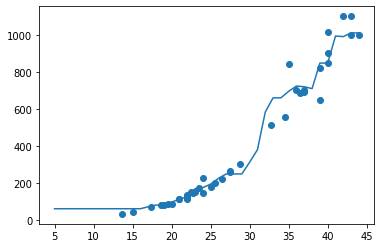 n_neighbors가 5로 설정된 그래프
n_neighbors가 5로 설정된 그래프
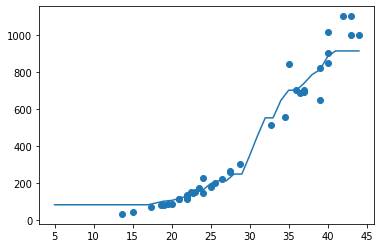 n_neighbors가 10으로 설정된 그래프
n_neighbors가 10으로 설정된 그래프
이웃을 많이 참조할 수록 모델이 단순해졌다.
선택 미션
모델 파라미터 설명.
모델 파라미터는 머신러닝 알고리즘이 찾은 값. 많은 머신러닝 알고리즘의 훈련 과정은 최적의 모델 파라미터를 찾는 것. k-최근접 이웃 등은 훈련 세트를 저장하는게 훈련의 전부인데 이를 사례 기반 학습이라고 부름.