혼자 공부하는 머신러닝 + 딥러닝 1주차
- 혼자 공부하는 머신러닝 + 딥러닝 1주차
- 혼자 공부하는 머신러닝 + 딥러닝 2주차
- 혼자 공부하는 머신러닝 + 딥러닝 3주차
- 혼자 공부하는 머신러닝 + 딥러닝 4주차
- 혼자 공부하는 머신러닝 + 딥러닝 5주차
- 혼자 공부하는 머신러닝 + 딥러닝 6주차 (완)
머신러닝을 정리할 겸 한빛미디어가 진행하는 혼공 학습단 5기에 참여했다. 1, 2장에 대해 학습을 진행했다.
기본 미션
학습한 내용 풀이
책이 구글 클라우드에서 수행되는 주피터 기반의 코랩으로 진행되는게 흥미로웠다.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
물고기의 길이와 무게의 데이터다. 데이터는 bitly 서비스에 올라와 있어서 직접 입력할 필요가 없었다.
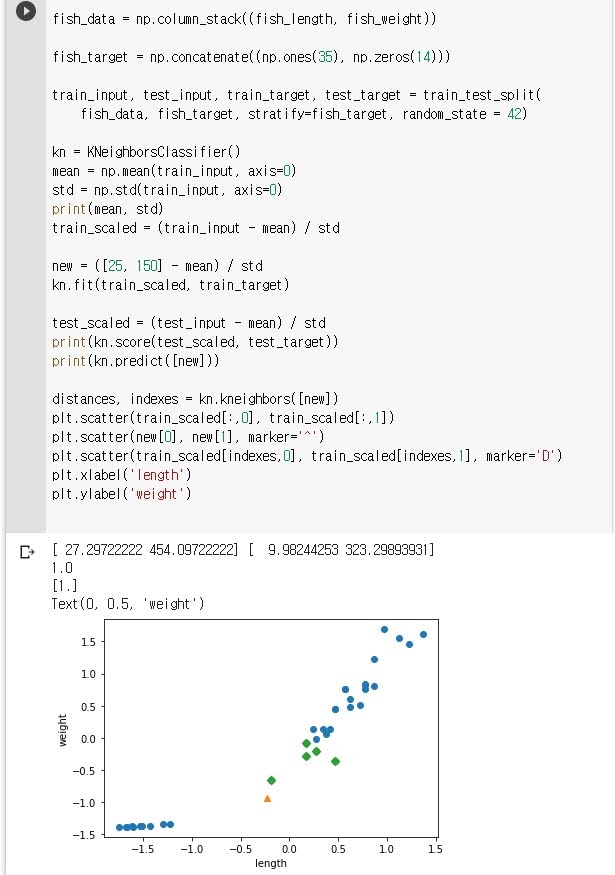
fish_data = np.column_stack((fish_length, fish_weight))
np.column_stack을 이용해서 fish_length와 fish_weight를 합친 2차원 배열 fish_data를 만들었다.
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
타겟 데이터를 도미와 빙어로 나누었는데 순서대로 빙어를 1로 도미, 0을 빙어로 했다. np.ones와 np.zeros를 이용해 연속으로 생성하고 np.concatenate로 합쳤다.
train_input, test_input, train_target, test_target = train_test_split(
fish_data, fish_target, stratify=fish_target, random_state = 42)
fish_data와 fish_target을 학습용(train_)과 검증용(test_)로 나누었다. 분류를 할 때 random_state를 지정하게 했는데 이 때문에 책의 결과와 독자의 결과가 같다. stratify는 클라스의 종류에 맞추어 비율이 비슷하게 분리하기 위한 것. 이 설정이 없으면 학습용과 검증용의 데이터에서 어떤 데이터엔 도미가 더 많을 수 있고 어떤 데이터는 빙어가 더 많을 수 있다.
kn = KNeighborsClassifier()
mean = np.mean(train_input, axis=0)
std = np.std(train_input, axis=0)
train_scaled = (train_input - mean) / std
K-최근접 분류를 위해 KNeighborsClassifier 인스턴스를 만들었다.
길이와 무게의 스케일이 다르기 때문에 맞추기 위해 mp.mean으로 평균을 mp.std로 표준 편차를 구했다. axis는 평균을 구할 데이터의 방향인데 0은 세로 방향, 1은 가로방향이라고 외우면 될 듯 하다.
값을 계산 한 이후 train_scaled를 계산하는데 Numpy에서는 train_input - mean으로 전체 값에 대해 평균만큼 뺄 수 있다. 길이는 모두 길이의 평균을 빼고 표준 편차로 나누어지고 무게 역시 마찬가지다.
new = ([25, 150] - mean) / std
kn.fit(train_scaled, train_target)
우리가 알고 싶은 값 [25, 150]도 평균과 표준 편차로 다듬어 준다.
스케일 처리된 학습 데이터와 타겟으로 학습을 시킨다.
test_scaled = (test_input - mean) / std
테스트 데이터에 대해서도 표준점수로 변환한다.
print(kn.score(test_scaled, test_target))
print(kn.predict([new]))
kn.score는 학습된 모델에 대해 테스트 데이터와 타겟 데이터를 가지고 얼마자 잘 나오는지 점수르 검증해준다.
kn.predict를 가지고 new가 도미인지 빙어인지 알아본다.
distances, indexes = kn.kneighbors([new])
new가 어떤 데이터와 가깝고 거리가 얼마나 되는지 확인한다.
plt.scatter(train_scaled[:,0], train_scaled[:,1])
학습 데이터로 산포도를 찍고.
plt.scatter(new[0], new[1], marker='^')
new가 어디에 속하는지도 찍어 보고.
plt.scatter(train_scaled[indexes,0], train_scaled[indexes,1], marker='D')
new에서 가까운 데이터는 다른 모양으로 찍어본다.
plt.xlabel('length')
plt.ylabel('weight')
x 라벨과 y 라벨을 지적했다.
선택 미션
2-1절 문제 풀이
- (1) 지도 학습
- (4) 샘플링 편향
- (2) 행: 샘플, 열: 특성